
Table of contents
1. Lattice fundamentals
1.1 Lattices
1.2 Computational lattice problems
1.3 Shortest vector problem
1.4 Closest vector problem
2. LWE fundamentals
2.1 Learning with errors
2.2 Decisional LWE
2.3 Linking LWE to computational lattice problems
2.4 LWE-based encryption schemes
2.5 Flavors of LWE: Ring-LWE and Module-LWE
3. Kyber
4. Dilithium
5. Bibliography
1. Lattice fundamentals
1.1 Lattices
Definition 1.1. (lattice, basis)

Definition 1.2. (lattice, rank, dimension, full-rank lattice)
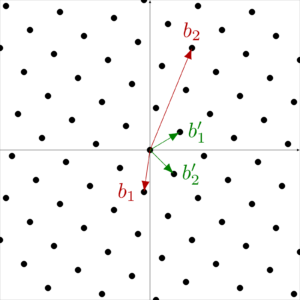
1.2 Computational lattice problems
- Let \(g_1, ..., g_k \in \mathbb{R}^n\) be a set of vectors generating the lattice \(L\). Calculate a basis \(b_1, ..., b_m \in \mathbb{R}^n\) of \(L\).
- Let \(L\) be a lattice. Evaluate whether a given vector \(c\) is an element of \(L\).
Other computational lattice problems appear to be generally hard and are even believed to be resistant against Shor’s algorithm. Therefore, they are interesting candidates for usage in post-quantum-cryptography. These problems are presented in the following.
1.3 Shortest vector problem
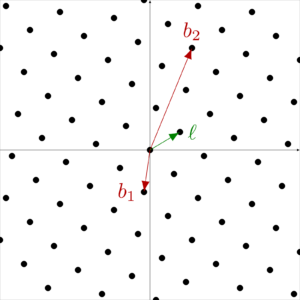
1.4 Closest vector problem
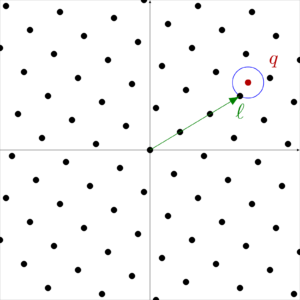
2. LWE fundamentals
2.1 Learning with errors
2.2 Decisional LWE
2.3 Linking LWE to computational lattice problems
Consider an LWE problem of the form
To give an intuition of the relationship between learning with errors and the shortest vector problem, consider the lattice
2.4 LWE-based encryption schemes
This section aims to serve as a high-level introduction to LWE-based encryption schemes, so that their basic idea can be easily understood. The following simplified example will only be used to transmit a message consisting of a single bit, but it can be trivially extended to transmit a bitstring of any desired length.
which can be equivalently represented as
in a compact form.
This means we have found a way to indirectly transmit about the same value in two separate ways and we have done so unnoticeable by a third person: Without knowledge of \(s\) it cannot be deduced how close exactly these values are to each other (dLWE assumption).
2.5 Flavors of LWE: Ring-LWE and Module-LWE
Most early practical implementations of LWE-based cryptography, such as the NewHope scheme [ADPS15], use Ring-LWE. However, it was shown that Ring-LWE possibly provides more attack surface, so that a Ring-LWE scheme is at most as secure as an equally-parameterized Module-LWE scheme [PP19]. For that reason, NIST has decided not to consider Ring-LWE schemes in the third round.
| Plain LWE | Ring-LWE | Module-LWE | ||
|---|---|---|---|---|
| \(\mathbf{A}\) | \(\mathbb{Z}_q^{n \times m}\) | \(\mathbb{Z}_q[x]/f\) | \(( \mathbb{Z}_q[x]/f)^{n \times m}\) | |
| \(\mathbf{\cdot}\) | matrix mult. | polynomial mult. | matrix mult. | |
| \(\mathbf{s}\) | \(\mathbb{Z}_q^m\) | \(\mathbb{Z}_q[x]/f\) | \(( \mathbb{Z}_q[x]/f)^m\) | |
| \(\mathbf{b,e}\) | \(\mathbb{Z}_q^n\) | \(\mathbb{Z}_q[x]/f\) | \(( \mathbb{Z}_q[x]/f)^n\) | |
3. Kyber
Input: none
1. Generate \(
A \in R_q^{k \times k} \)
2. Sample \(
s \in R_q^k \) with coefficients from \(
B \)
3. Sample \(
e \in R_q^k \) with coefficients from \(
B \)
4. Calculate \(
b = As + e \)
Output: public key \( pk = (A, b) \), secret key \( s \)
The Kyber PKE encryption looks similar to the LWE-based encryption scheme introduced in section 2.4 expanded to a Module-LWE setting.
Input: public key \( pk = (A, b) \), message \( m \in \{0,1\}^{256}\)
1. Sample \(
r \in R_q^k \) with coefficients from \(
B \)
2. Sample \(
e_1 \in R_q^k\) with coefficients from \(
B \)
3. Sample \(
e_2 \in R_q \) with coefficients from \(
B \)
4. Calculate \(
u = A^Tr+e_1 \)
5. Calculate \(
v = b^Tr + e_2 + toRing(m)\)
Output: ciphertext \( c=(u,v)\)
Input: secret key \( s \), ciphertext \( c = (u,v)\)
1. Calculate \( m^* = v-s^Tu \)
Output: message \( m = fromRing(m^*)\)
To construct a CCA-secure KEM from the given PKE, a variant of the Fujisaki-Okamoto transformation (FO-transformation) is used. Fujisaki and Okamoto [FO13] presented the first generic transformation from asymmetric and symmetric encryption schemes to a secure hybrid encryption scheme. Later, Hofheinz, Hövelmanns and Kiltz [HHK17] extended the work of Fujisaki and Okamoto and presented a generic transformation toolkit including a transformation of a PKE scheme into a secure KEM.
Input: none
1. Generate \(
\sigma \in \{0,1\}^{256} \)
2. Generate \(
(pk, s) = PKE.keyGen()\)
Output: public key \( pk \), secret key \( sk = (s,\sigma) \)
Input: public key \( pk \)
1. Generate message \(
m \in \{0,1\}^{256}\)
2. Calculate \(
(K',r) = H_1(H_2(m) \mid\mid H_2(pk))\)
3. Calculate \(
c = PKE.enc_r(pk, H_2(m)) \)
4. Calculate \(
K = KDF(K' \mid\mid H_2(c))\)
Output: encapsulation \( c \), shared secret \( K \)
The decapsulation routine calculates the required values analogously to the encapsulation routine.
Input: public key \( pk \), secret key \( sk = (s,\sigma) \), encapsulation \( c \)
1. Calculate \(
H_m = PKE.dec(s, c)\)
2. Calculate \(
(K',r') = H_1(H_m \mid\mid H_2(pk))\)
3. Calculate \(
c' = PKE.enc_{r'}(pk, H_m) \)
4. If \(
c = c' \text{, set } K = KDF(K' \mid\mid H_2(c))\)
5. If \(
c \neq c' \text{, set } K = KDF(\sigma \mid\mid H_2(c))\)
Output: shared secret \( K\)
| \(n\) | \(k\) | \(q\) | \(\delta\) | |
|---|---|---|---|---|
| Kyber512 | 256 | 2 | 3329 | 2-139 |
| Kyber768 | 256 | 3 | 3329 | 2-164 |
| Kyber1024 | 256 | 4 | 3329 | 2-174 |
4. Dilithium
Input: none
1. Generate \(
A \in R_q^{k \times l}\)
2. Sample \(
s \in R_q^l\) with small coefficients
3. Sample \(
e \in R_q^k \) with small coefficients
4. Calculate \(
b = As + e\)
Output: public key \( pk = (A, b)\), secret key \( s \)
Input: public key \( pk = (A, b) \), secret key \( s\), message \( m \in \{0,1\}^{\star}\)
Until \( z\) is valid:
1. Sample \(
y \in R_q^l\) with small coefficients
2. Calculate \(
w = round(Ay) \)
3. Calculate \(
c = H(m \mid\mid w)\)
4. Calculate \(
z = y + cs\)
Output: signature \( \sigma = (z,c)\)
Input: public key \( pk = (A, b) \), message \( m \in \{0,1\}^{\star}\), signature \( \sigma = (z,c)\)
1. Calculate \(
w' = round(Az-bc)\)
2. Calculate \(
c' = H(m \mid\mid w')\)
Output: valid if \( c = c'\), else invalid
| \(n\) | \((k,l)\) | \(q\) | \(\#reps\) | |
|---|---|---|---|---|
| Dilithium 2 | 256 | (4,4) | 8380417 | 4.25 |
| Dilithium 3 | 256 | (6,5) | 8380417 | 5.1 |
| Dilithium 5 | 256 | (8,7) | 8380417 | 3.85 |
This blog post is part of our blog series »Post-Quantum Cryptography in Practice« and an excerpt of the study »A Mathematical Perspective on Post-Quantum Cryptography«, which gives an overview of the round-three finalist of NIST’s post-quantum cryptography standardization process. It introduces the mathematical fundamentals of the lattice-based key encapsulation mechanisms (KEMs) CRYSTALS-Kyber, NTRU and SABER; the code-based KEM Classic McEliece; the lattice-based signature schemes CRYSTALS-Dilithium and FALCON; and the multivariate-based signature scheme Rainbow.
5. Bibliography
[ABD+21]
Roberto Avanzi, Joppe Bos, Léo Ducas, Eike Kiltz, Tancr`ede Lepoint, Vadim Lyubashevsky, John M. Schanck, Peter Schwabe, Gregor Seiler, and Damien Stehlé. CRYSTALSKYBER: Algorithm specifications and supporting documentation, Jan. 2021.
[ADPS15]
Erdem Alkim, Léo Ducas, Thomas Pöppelmann, and Peter Schwabe. Post-quantum key exchange – a new hope. Cryptology ePrint Archive, Report 2015/1092, 2015. https://ia.cr/2015/1092.
[BCD+16]
Joppe Bos, Craig Costello, Leo Ducas, Ilya Mironov, Michael Naehrig, Valeria Nikolaenko, Ananth Raghunathan, and Douglas Stebila. Frodo: Take off the ring! practical, quantumsecure key exchange from lwe. pages 1006–1018, 10 2016.
[BDK+20]
Shi Bai, Léo Ducas, Eike Kiltz, Tancrede Lepoint, Vadim Lyubashevsky, Peter Schwabe, Gregor Seiler, and Damien Stehlé. CRYSTALS-Dilithium: Algorithm specifications and supporting documentation, Oct. 2020.
[BG14]
Shi Bai and Steven D. Galbraith. An improved compression technique for signatures based on learning with errors. In Josh Benaloh, editor, Topics in Cryptology – CT-RSA 2014, pages 28–47, Cham, 2014. Springer International Publishing.
[CJL+16]
Lily Chen, Stephen Jordan, Yi-Kai Liu, Dustin Moody, Rene Peralta, Ray Perlner, and Daniel Smith-Tone. Report on Post-Quantum Cryptography. Technical Report NIST Internal or Interagency Report (NISTIR) 8105, National Institute of Standards and Technology,
April 2016.
[FO13]
Eiichiro Fujisaki and Tatsuaki Okamoto. Secure Integration of Asymmetric and Symmetric Encryption Schemes. Journal of Cryptology, 26(1):80–101, January 2013.
[HHK17]
Dennis Hofheinz, Kathrin Hövelmanns, and Eike Kiltz. A Modular Analysis of the Fujisaki-Okamoto Transformation. In Yael Kalai and Leonid Reyzin, editors, Theory of Cryptography, volume 10677, pages 341–371. Springer International Publishing, Cham, 2017. Series Title: Lecture Notes in Computer Science.
[LPR10]
Vadim Lyubashevsky, Chris Peikert, and Oded Regev. On ideal lattices and learning with errors over rings. In Henri Gilbert, editor, Advances in Cryptology – EUROCRYPT 2010, pages 1–23, Berlin, Heidelberg, 2010. Springer Berlin Heidelberg.
[LS12]
Adeline Langlois and Damien Stehle. Worst-case to average-case reductions for module lattices. Cryptology ePrint Archive, Report 2012/090, 2012. https://ia.cr/2012/090.
[Lyu12]
Vadim Lyubashevsky. Lattice signatures without trapdoors. In David Pointcheval and Patrick Schaumont, editors, EUROCRYPT 2012 – 31st Annual International Conference on the Theory and Applications of Cryptographic Techniques, Cambridge, UK, April 15-19, 2012., volume 7237 of Lecture Notes in Computer Science, pages 738–755, Cambridge, United Kingdom, April 2012. Springer.
[PP19]
Chris Peikert and Zachary Pepin. Algebraically structured lwe, revisited. Cryptology ePrint Archive, Report 2019/878, 2019. https://ia.cr/2019/878.
[Reg09]
Oded Regev. On lattices, learning with errors, random linear codes, and cryptography. Journal of the ACM, 56(6):34:1–34:40, September 2009.
Authors

Maximilian Richter
Maximilian Richter is an IT security researcher and passionate about mathematical aspects of cryptography. After studying both mathematics and computer science and several years of practical experience as a working student with focus on risk and threat modeling, design of secure system architectures and cryptographic software development, he does research at Fraunhofer AISEC in the areas of post-quantum cryptography, quantum cryptanalysis, secure systems and digital identities since 2020.

Jasper Seidensticker
Jasper Seidensticker is an M.Sc. student of mathematics at FU Berlin and works at Fraunhofer AISEC as a student researcher since 2021. His main fields of research are cryptography and cryptanalysis with a focus on post-quantum-cryptography, especially lattice-based primitives.

Magdalena Bertram
Magdalena Bertram has been a student researcher at Fraunhofer AISEC in the Secure Software Engineering department since 2020. She completed her Bachelor’s degree in mathematics and is currently writing her Master’s thesis in computer science in the field of lattice-based signature schemes. Her areas of focus include post-quantum cryptography, cryptanalysis, and digital identities.






