
Eine Corona-Infektion mittels Sprachaufnahmen sicher erkennen? [1] Deepfakes verlässlich identifizieren? KI macht’s möglich. Diverse Wettbewerbe bieten Datensätze, um Machine-Learning-Modelle auf diese Anwendungsfälle hin zu „trainieren“, und machen dadurch eine Vielzahl wissenschaftlicher Publikationen dazu möglich [2]. Immer höhere Erkennungsraten etwa von Deepfakes lassen hoffen, dass sich diese bald sicher und zuverlässig erkennen und in sozialen Medien automatisiert entfernen lassen. Künstliche Intelligenz, so scheint es, kann bisher unlösbar geglaubte Probleme lösen und übertrifft dabei oft den Menschen, wie z. B. im Schach, bei dem beliebten Brettspiel „GO“ oder in komplexen Videospielen wie „StarCraft II“ [4].
Doch Vorsicht ist geboten: Während KI in manchen Bereichen nachweisbar erfolgreich ist, lassen sich an anderer Stelle kaum Fortschritte feststellen. So wird beispielsweise in einem Artikel des MIT ausgeführt, dass keines der über 100 zur Covid-19-Diagnose entwickelten Tools so zuverlässig war, dass es im klinischen Umfeld eingesetzt werden konnte [5]. Und mehr noch: Mancher Wissenschaftler befürchtet sogar einen möglichen Schaden für die Patient*innen.
Diese Beobachtungen sind konsistent mit anderen Studien und Erfahrungen aus der wissenschaftlichen Praxis [6] [7]: KI-Modelle funktionieren in der Realität manchmal deutlich schlechter, als die Labortests erwarten lassen. Aber warum ist das so? Ist KI nur ein neuer technologischer Hype, von dem wir uns in einigen Jahren ernüchtert abwenden werden?
Warum KI funktioniert und warum sie scheitert
Um zu verstehen, warum KI manchmal exzellente Resultate liefert (Schach, Go, Starcraft) und manchmal auf ganzer Länge scheitert (Covid-Diagnose), müssen wir verstehen, wie KI funktioniert. KI ist eigentlich besser beschrieben mit dem Wort ‚Mustererkennung‘: Die Modelle lernen kein semantisches Verstehen wie wir Menschen, sondern lernen lediglich Muster – und zwar basierend auf Beispielen in einem Datensatz. Nehmen wir etwa das Problem, Pferde und Kamele zu unterscheiden. Anhand vieler Beispielbilder lernt die KI, dass z. B. Farbgebung, Größe und Form dieser Tiere unterschiedlich sind. Sie wird aber auch lernen, dass eine Koppel im Hintergrund fast ausschließlich mit der Präsenz von Pferden korreliert. Und das ist die Tücke: Wenn sich nun in der echten Welt ein Kamel auf eine Koppel verirrt, so ist die KI verwirrt, denn sie hat noch nie ein Kamel auf einer Koppel gesehen. Hier liegt der Unterschied zum Menschen: Auch wenn wir eine derartige Situation noch nie gesehen haben, so können wir sie uns vorstellen – ganz im Gegensatz zur KI.
Dieses Beispiel illustriert ein grundlegendes Problem in KI-Erkennungsalgorithmen: Wir wissen nicht (genau), was diese Modelle lernen. Wir können nur sagen: Es werden alle Korrelationen in den Daten erfasst, auch solche, die eigentlich nichts zum Problemverständnis beitragen. Sind die Bilder von Pferden vornehmlich abends gemacht? Vielleicht mit einer anderen Kamera als die Kamelbilder? War gegebenenfalls ein kleines Staubkörnchen auf der Linse, als die Pferde aufgenommen wurden? Das Modell wird lernen: „Staubkorn“ und „Abendstimmung“ ist gleich „Pferd“, sonst „Kamel“. Dies funktioniert dann treffsicher auf dem vorliegendem Datensatz und die Wissenschaftler*innen sind überzeugt: Unser Modell funktioniert. Aber natürlich funktioniert es nicht wirklich, sondern nur im Labor unter genau diesen Umständen und mit genau diesen „Shortcuts“. Die wissenschaftliche Gemeinschaft wird sich dieses Problems immer stärker bewusst und hat ihm nun einen Namen gegeben: „Shortcut Learning“, d. h. das Lernen von falsch allokierten Bedeutungsträgern [8].
Dieses Phänomen kann auch das Fehlschlagen der KI-Modelle zur Covid-Erkennung erklären: Z. B. kommen Bilder von Personen mit bzw. ohne nachgewiesene Corona-Infektion vornehmlich aus verschiedenen Krankenhäusern. Das Modell lernt also nicht, „Covid“ und „Nicht-Covid“ zu unterscheiden, sondern die Aufnahmen von Krankenhaus A bzw. Krankenhaus B. Ähnliches gilt z. B. für Schläuche oder anderes medizinisches Gerät, welches bei erkrankten Personen deutlich häufiger auf dem Bild zu sehen ist als bei gesunden [9].
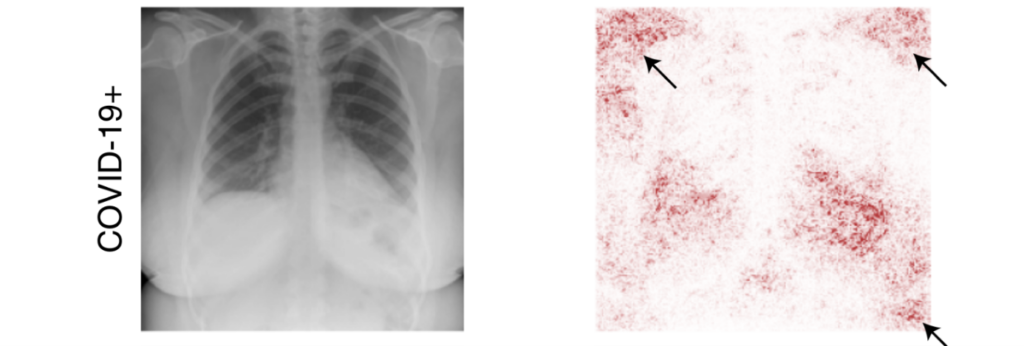
Scan der Brust einer positiv auf Covid-19 getesteten Patientin (links). Regionen, die zur Klassifikation eines KI-Modells beitragen (rechts, in rot). Zu sehen ist, dass viel Aufmerksamkeit der KI auf Regionen außerhalb der Lunge fällt: Die Klassifikation der Patientin als Covid-19 positiv erfolgt also auch anhand von Shortcuts, wie an der Position der Schulter (Pfeil oben links). Grafik entnommen aus [9].
Overfitting: Ein Datensatz als Maß aller Dinge
Der systematische Unterschied
Der richtige Umgang mit ML-Shortcuts
Was kann nun getan werden, um ein datengetriebenes Klassifikationsproblem zu lösen? Wie so oft gibt es keinen „Quick Fix“, aber eine Reihe von Best Practices:
- Zuerst sollte man, falls man selbst Daten sammelt, den Prozess kritisch hinterfragen und dafür sorgen, dass die Zielklasse bzw. das Klassifikationsziel nicht mit offensichtlichen Attributen (wie z.B. Datenquelle, Kameratyp, etc.) korreliert. Hat man etwa einen großen Corpus an Daten und lässt diese von Menschen labeln, so sollte jeder Arbeiter (d. h. die Person, die das Labeln des Datensatzes übernimmt) Beispiele von allen Klassen bearbeiten, anstatt jeweils nur eine Klasse.
- Weiterhin kann man die Datenlage verbessern, indem man die Daten aus möglichst vielen heterogenen Quellen sammelt – vorausgesetzt, jede Quelle trägt in etwa gleich viele Datenpunkte jeder Klasse bei (ansonsten gibt es ein Shortcut wie aus dem Beispiel zuvor, wo das Krankenhaus mit Covid-19-Prävalenz korreliert). Ein derartiger Datensatz ist, falls eine Quelle Shortcuts enthält, zumindest nicht vollständig fehlerhaft.
- Ein Muss ist der Einsatz von Explainable-AI-Techniken (XAI). Dies sind Methoden aus dem Bereich Machine Learning, die aufzeigen, was das Modell lernt (siehe etwa Fig. 1 oben, rechts). Dadurch kann man feststellen, ob das KI-Modell semantisch korrekte Features oder Shortcuts lernt.
- Letztlich kann man auf automatisierte Techniken zur Entfernung von Shortcuts zurückgreifen. Dies funktioniert, indem man z. B. definiert, wie viel Prozent Vorhersagekraft ein Pixelstück maximal haben darf, und dann durch Loss-Funktionen entsprechend „zu starke“ bearbeitet bzw. semantisch dominante Pixelflächen abändert. Diese Methoden stecken allerdings noch in den Kinderschuhen.
(Noch) ist also die Kompetenz des KI-Entwicklers gefragt, das Thema „ML-Shortcuts“ zu verstehen und das Modell vor allem mit XAI-Methoden kritisch auf den Lernerfolg zu überprüfen. Dies heißt insbesondere, blindes Vertrauen auf Benchmarks und Test-Set-Performance abzulegen und sich klarzumachen: Machine-Learning-Modelle leisten Mustererkennung und lernen jede Art von Korrelation – erwünscht oder unerwünscht. Der Mensch hat dann zu bewerten, ob das Gelernte sinnhaft ist oder nicht.
Autor

Nicolas Müller
Dr. Nicolas Müller hat an der Universität Freiburg Mathematik, Informatik und Theologie auf Staatsexamen studiert und 2017 mit Auszeichnung abgeschlossen. Er ist seit 2017 wissenschaftlicher Mitarbeiter am Fraunhofer AISEC in der Abteilung ‘Cognitive Security Technologies’. Seine Forschung konzentriert sich auf die Verlässlichkeit von KI-Modellen, ML-Shortcuts und Audio-Deepfakes.





