
Machine learning has been astronomically popular since the launch of OpenAI’s ChatGPT in 2022. Even before that, it had experienced a resurgence. After mostly theoretical works dating back to 1959, the usage of GPUs for accelerated learning [1] has unlocked the deep learning revolution. The field has gained popularity in numerous promising real-world applications – including the discovery of new pharmaceutically relevant compounds using graph neural networks, speeding up medical and biological research by predicting protein structures, and the automation of industry processes through vision models, among others. Large language models (LLMs) such as ChatGPT and other types of generative models such as StabilityAI’s Stable Diffusion for image generation and Google’s Veo2 video generation model are the most popular types of models outside of academia and industry. That’s because the output is useable and understandable by anyone – unlike a protein structure prediction model. In addition, it can be shared easily on social media (text, photo, video). Still, they’ve put machine learning (ML) and artificial intelligence (AI) as a whole into the spotlight, sparking increased interest in industry applications beyond of those types of models.
As AI begins to inhabit an increasingly important role in society, ethical questions around intellectual property, privacy, fairness, explainability, responsibility and many others are more important now than ever before.
Why do we need private machine learning?
ML models are trained on a vast corpus of data, collected by so-called scrapers that crawl the entire internet in search for more data. Search engines like Google or Bing have been scraping the internet for years to populate search indexes, to the benefit of anyone looking for information. This kind of scaling allows ML models to exhibit emergent abilities – behavior that only occurs past a certain training scale and can’t be predicted by extrapolating smaller training scales [2]. It is these emergent abilities that make large language models (LLMs) truly exciting: They can solve new tasks just from being provided a few examples in the prompt (known as few-shot prompting) or output is improved by reasoning about it (known as chain of thought).
While training on internet-scale data is beneficial for model performance and unlocks many of the unique properties of LLMs, it also raises the question of where this data originates.
Data Origins
When we say »internet-scale data« what does that actually mean?
Training datasets contain virtually everything available online: forum posts, tweets, Reddit threads, blogs, tutorials, company websites, personal pages, online stores… If it’s indexed by search engines like Google, it’s probably been scraped and added to AI training data.
This creates some serious challenges:
- Professional writers and artists aren’t being compensated when their work trains AI
- People’s personal information is used without their consent
- Some content was never meant to be public in the first place
Data Reconstruction
Models memorize at least some of the data they’ve been trained on [3]. In the case of generative models like LLMs, which generate natural language, and of diffusion models, which generate images, memorization can lead to reconstruction of training data when you use the model [4],[5].
These models keep »copies« of training data and sometimes reproduce exact replicas when prompted. For models trained on internet-scale data, this has been shown to leak personal information that was never meant to be public.
Figures 1 and 2 show these effects. In the first example, a generative model for images is trained on various images with captions. If we prompt the model with a text similar to the caption of an image, the model generates an almost exact replica of the training sample. In the second example, a language model is trained on a large corpus of text which happens to include personally identifiable information (PII) of an individual. Using a specific prompt, the model will reproduce the full name, phone number and email. This information is real and the individual was contacted by the authors of the paper to obtain authorization for including them in the publication, but their information was redacted.

Figure 1: An image (left) is included in the model training. When prompted with a similar prompt, the model reproduces an almost exact replica (right) of the training image. Source: [4].

Figure 2: Given a specific prefix, the GPT-2 language model reproduces personally identifiable information of an individual that was included in the training set. Source: [5].
Protecting the Privacy of Data Subjects
Fortunately, there’s a method to ensure that individual data points cannot be recovered, called Differential Privacy (DP) [6]. Let’s decompose what it means:
In plain English:
- We want to protect data from being exposed (that’s the »privacy« part)
- »Differential« we’re focusing on how the output of an algorithm changes between neighboring datasets, i.e., when a single new data point is added to our existing dataset*
DP guarantees that if we train one model on a dataset and another model on that same dataset plus one additional point, the two models will behave nearly indistinguishable. We can configure how much difference is allowed between them.**
With strict privacy settings, adding a new data point can only slightly change the model’s behavior. This means the model simply cannot memorize or reproduce individual training samples!
Does DP apply to just one added sample then?
No! We analyze each sample and consider what happens if we add or remove it. The privacy guarantee we end up with is the worst-case scenario across all samples. Thus, while we technically state the guarantee for only a single sample, it applies to all samples simultaneously.
How do we DP-fy machine learning?
There is a great tutorial with that exact name: How to DP-fy ML: A Practical Guide to Machine Learning with Differential Privacy [7]. Essentially, DP-fying anything – including ML – boils down to two parts:
- Limit the extent of influence any single sample can have
- Add randomness to the process
In practice, we typically »clip« each data sample or its gradient (the direction the model needs to update to learn from that sample), and then add some noise.***
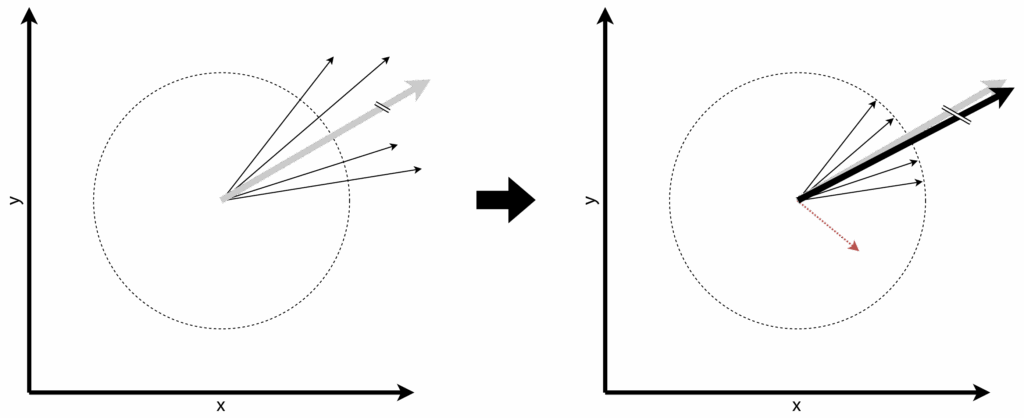

Figure 3: An illustration of how to privatize machine learning. The left side shows non-private machine learning. Data points contribute their gradients and the overall gradient is the sum of those gradients. The right side shows the private counterpart.
Figure 3 shows an example. We have four private data points and want to train a model. In the non-private case on the left side, we’d calculate how to update the model based on each point’s »gradient« – but using these directly would leak information about the private points. Instead, on the right side, we compute a private sum of the gradients by clipping them to a certain length first and adding noise.
The resulting private sum points roughly in the same direction as the non-private sum – it’s just slightly rotated and smaller. In the context of ML, this difference usually isn’t too problematic.
Amplification of Biases
One tricky issue with privacy-preserving ML is that it can amplify biases against underrepresented groups. Here’s why:
- Minority data points often point in different directions than majority data: Since minority groups have different characteristics, the model updates needed to learn those points often differ from the majority.
- Minority gradients are typically larger: With fewer examples of minority groups in the training data, the model makes bigger errors on these points, leading to larger
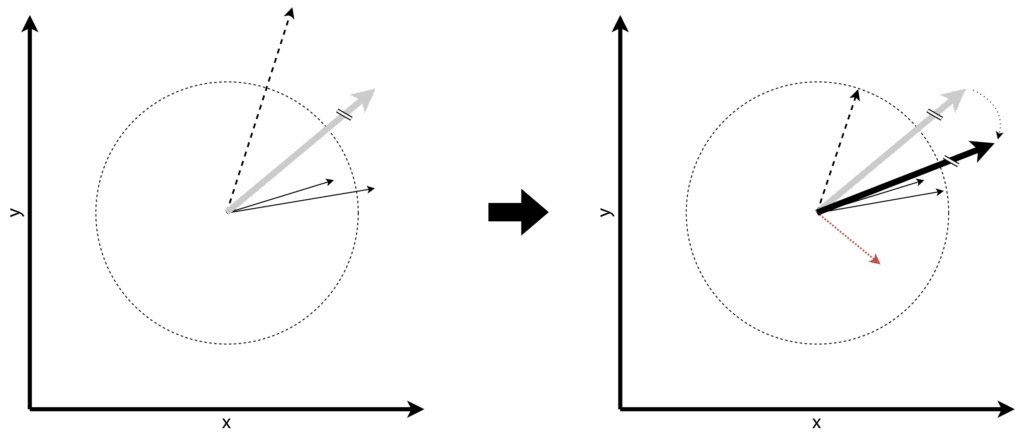

Figure 4: By privatizing the training, the gradient will systematically rotate away from underrepresented data samples.
Figure 4 shows this example. When we clip gradients for privacy, we end up clipping minority gradients more often (since they’re larger). As the figure shows, this systematically rotates the overall gradient toward the majority group [9].
In addition, by limiting the influence of any single sample to the model (which is essential for privacy), we make it harder for the model to learn from rare examples.
Addressing the Bias Problem
To address these bias challenges, we propose Differentially Private Prototype Learning (DPPL) – a simple yet effective approach that maintains privacy while treating all data groups fairly.
DPPL: A Prototype-Based Approach
Our method works by representing each class (whether majority or minority) with a single representative »prototype«. When classifying new data, we simply find which prototype it’s closest to. This approach:
- Eliminates the gradient-based bias issues mentioned earlier
- Provides strong privacy guarantees
- Maintains good performance for strongly underrepresented minorities
The intuition behind the prototype-based approach is inspired by Prototypical Networks [10] from the meta-learning field.
Figure 5 outlines our pipeline.
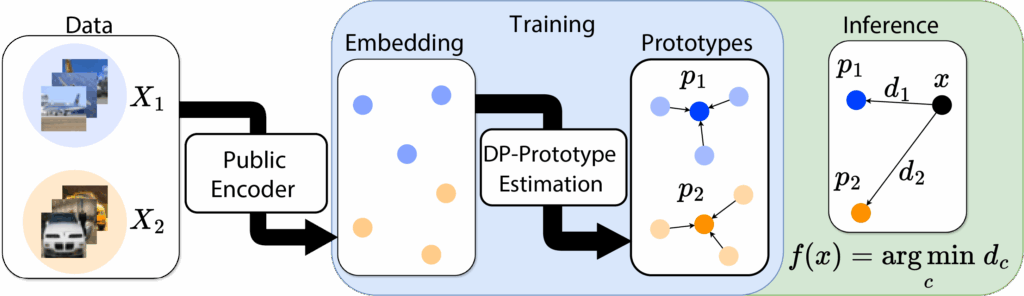
Figure 5: The concept of Differentially Private Prototypical Learning (DPPL) involves obtaining embeddings from an encoder and representing classes with a presentative prototype.
We first transform the private images using a publicly available encoder. The challenge is then to combine these private embeddings into representative prototypes without leaking individual data. To this end, we have developed two complementary approaches to obtain these prototypes under DP. Finally, to classify an unknown image, we transform it using the same encoder and look up which prototype is the closest.
DPPL-Mean: Private Averaging
The first method is DPPL-Mean. It creates prototypes through differentially private averaging, like our examples from above:
- We encode each private image into a feature vector
- We clip these vectors to limit any individual’s influence
- We add calibrated noise for privacy protection
- We aggregate these into a class prototype
Unlike in gradient-based learning, the feature vectors don’t vary in magnitude between majority and minority groups. This means our clipping operation treats all data equally, eliminating the bias amplification problem entirely.
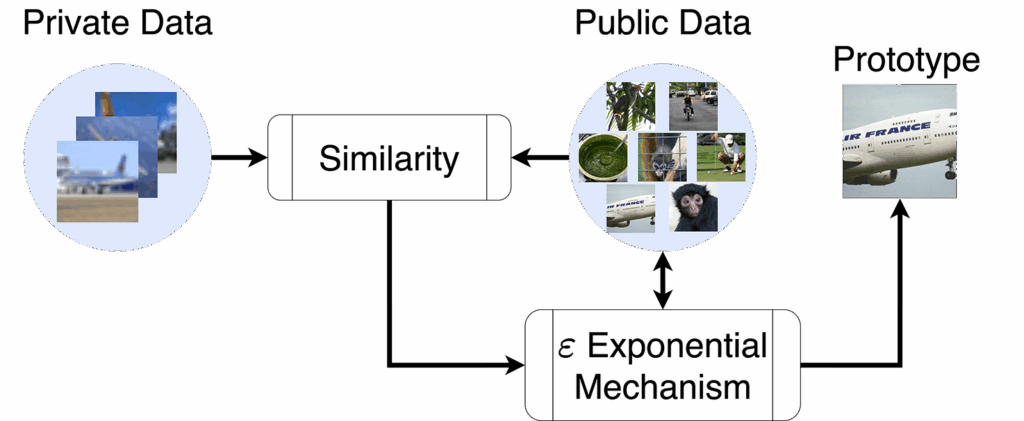
DPPL-Public: Finding Public Representatives
Our second approach, DPPL-Public, takes privacy protection even further. Instead of creating synthetic prototypes, we privately select the best representatives from a public dataset:
- We compare public images to our private training images
- Using the differentially private Exponential Mechanism, we select public images that best represent each private class
- These public images become our prototypes
This method further reduces privacy costs, as the private data is only used for a selection rather than to directly construct the prototype.
Results
Our methods achieve state-of-the-art performance on datasets with severely underrepresented classes, where the smallest class can be 10× to 100× smaller than the largest. In our experiments, DPPL increases accuracy on minority classes from 0% (with naïve differentially private methods) and 23% (with other fairness-oriented approaches) to over 70%, representing a more than threefold improvement over previous results. Importantly, this dramatic improvement comes without performance degradation for majority classes, proving that privacy and fairness can coexist without sacrifices.
Conclusion: Privacy and Fairness Together
Machine learning is transforming our world, but with great power comes great responsibility. As we’ve demonstrated, traditional privacy-preserving methods can inadvertently amplify biases against underrepresented groups — precisely against those who are often most vulnerable to privacy violations.
DPPL offers a practical solution that doesn’t force this trade-off. By using prototype-based learning with carefully designed privacy mechanisms, we can:
- Provide strong privacy guarantees that prevent data memorization and exposure
- Ensure fair performance across all demographic groups, even highly underrepresented ones
- Maintain high overall model utility and accuracy without compromising majority performance
Future works includes combining this approach with more flexible learning methods to increase adaptability and extending to other data modalities beyond images. Our research to date clearly demonstrates that privacy and fairness can and must coexist in machine learning systems. As AI continues to shape society, approaches like DPPL will be essential to ensure that technological progress benefits everyone equally while respecting fundamental rights to privacy.
Footnotes
* This is just one possible neighborhood definition, which gives us an Add/Remove-DP guarantee. Another popular way to define neighborhood would be to replace a single datapoint instead of adding one, called substitute-DP. We refer the interested reader to [7].
** Privacy leakage is often denoted as ϵ for pure DP, (ϵ, δ) for approximate DP, ρ for zero-concentrated DP, μ for Gaussian DP or Z for the Privacy Loss Random Variable.
*** There are other ways of achieving DP like using Lipschitz Continuity Constraints, but they are not widely used (yet) [8].
Bibliography
[1] K.-S. Oh and K. Jung, “GPU implementation of neural networks,” Pattern Recognition, vol. 37, no. 6, pp. 1311–1314, Jun. 2004, doi: 10.1016/j.patcog.2004.01.013.
[2] J. Wei et al., “Emergent Abilities of Large Language Models,” Oct. 26, 2022, arXiv: arXiv:2206.07682. doi: 10.48550/arXiv.2206.07682.
[3] V. Feldman, “Does Learning Require Memorization? A Short Tale about a Long Tail,” Jan. 10, 2021, arXiv: arXiv:1906.05271. Accessed: Jun. 05, 2023. [Online]. Available: http://arxiv.org/abs/1906.05271
[4] N. Carlini et al., “Extracting Training Data from Diffusion Models,” Jan. 30, 2023, arXiv: arXiv:2301.13188. Accessed: Sep. 05, 2023. [Online]. Available: http://arxiv.org/abs/2301.13188
[5] N. Carlini et al., “Extracting Training Data from Large Language Models,” 2021, pp. 2633–2650. Accessed: Nov. 19, 2024. [Online]. Available: https://www.usenix.org/conference/usenixsecurity21/presentation/carlini-extracting
[6] C. Dwork, F. McSherry, K. Nissim, and A. Smith, “Calibrating Noise to Sensitivity in Private Data Analysis,” in Theory of Cryptography, S. Halevi and T. Rabin, Eds., in Lecture Notes in Computer Science. Berlin, Heidelberg: Springer, 2006, pp. 265–284. doi: 10.1007/11681878_14.
[7] N. Ponomareva et al., “How to DP-fy ML: A Practical Guide to Machine Learning with Differential Privacy,” Journal of Artificial Intelligence Research, vol. 77, pp. 1113–1201, Jul. 2023, doi: 10.1613/jair.1.14649.
[8] L. Béthune et al., “DP-SGD Without Clipping: The Lipschitz Neural Network Way,” Oct. 2023. Accessed: Feb. 12, 2025. [Online]. Available: https://openreview.net/forum?id=BEyEziZ4R6
[9] M. S. Esipova, A. A. Ghomi, Y. Luo, and J. C. Cresswell, “Disparate impact in differential privacy from gradient misalignment,” in The eleventh international conference on learning representations, 2023. [Online]. Available: https://openreview.net/forum?id=qLOaeRvteqbx
[10] J. Snell, K. Swersky, and R. Zemel, “Prototypical Networks for Few-shot Learning,” in Advances in Neural Information Processing Systems, Curran Associates, Inc., 2017. Accessed: Aug. 30, 2023. [Online]. Available: https://proceedings.neurips.cc/paper_files/paper/2017/hash/cb8da6767461f2812ae4290eac7cbc42-Abstract.html
Author

Dariush Wahdany
Dariush Wahdany is a research associate at Fraunhofer AISEC and a PhD candidate at FU Berlin, focusing on privacy-preserving machine learning. Wahdany frequently shares his expertise as a speaker at venues including Google Research, Omnisecure, COSMO Consult, and the Health & Law Netzwerk Berlin, and supports information security courses at Freie Universität Berlin.
He completed his Master’s degree in Electrical Engineering, Information Technology, and Computer Engineering from RWTH Aachen and TU Delft in 2022. His prior practical experience includes developing cloud-based market simulation methods at Maon GmbH, which was awarded the BMWi Gründerpreis, researching international power and heat grids at IAEW RWTH Aachen, implementing electrical energy network automation at umlaut company (now part of Accenture), and supporting product and innovation management at Siemens Healthineers.
Contact: dariush.wahdany@aisec.fraunhofer.de






